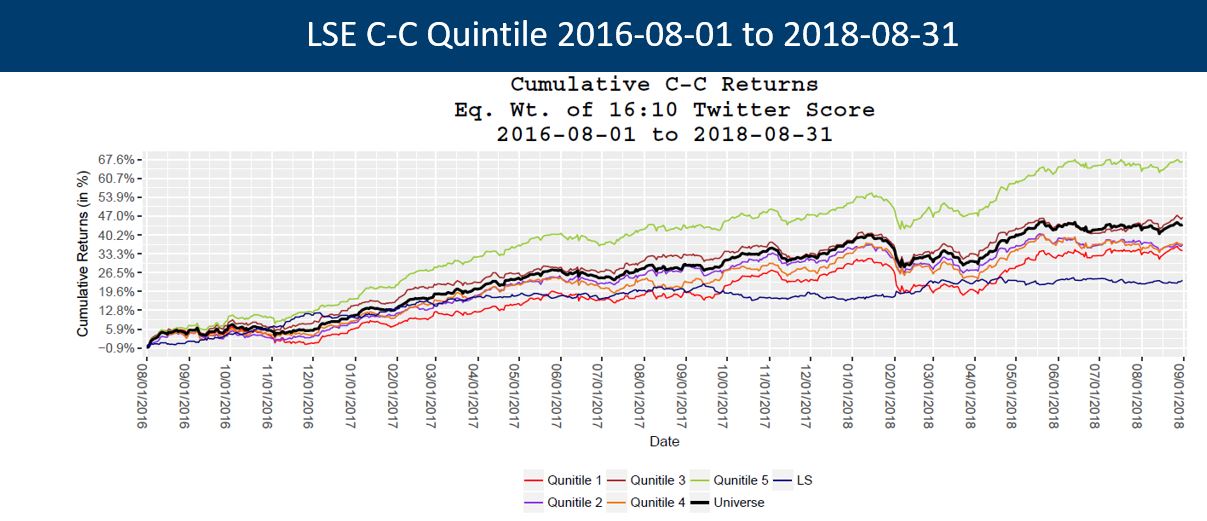
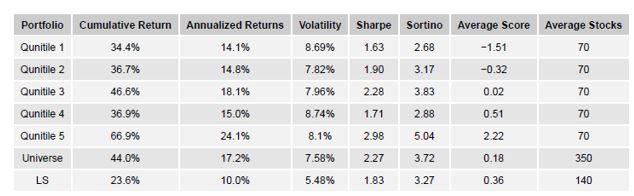
One of the most closely followed events on the corporate calendar are earnings calls. This gives executives the opportunity to comment on earnings and answer questions from those outside of the company. Using our patented Natural Language Processing, Social Market Analytics scores Earnings Call Transcripts in real time and creates metrics based on sentiment, word count, and section count. For this research, we look specifically at the question-and-answer section of call transcripts. The theory is that isolating the section of the call where executives aren’t controlling the topic of conversation will give a more accurate assessment of the sentiment surrounding earnings results. We use Sum of Sentiment to quantify the positivity of the call. Sum of Sentiment adds all the words and phrases tagged in the section with sentiment. The following histogram shows the distribution of the Sum of Sentiment variable.
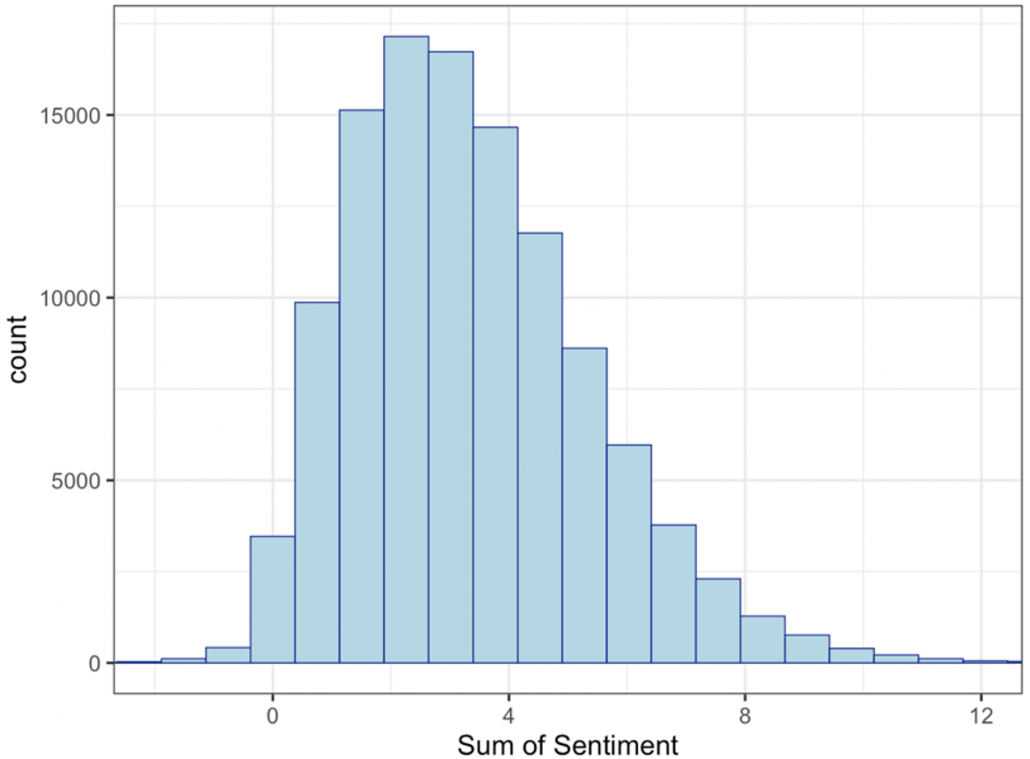
The Sum of Sentiment is centered around 3.5 and is roughly normal with a heavy tail skewing right. As executives of companies want to express good things to come, it makes sense that the sum is predominantly positive. Still some earnings calls are more positive than others. Based on the distribution of sentiment, we defined an extremely positive earning call as having a sum greater than 5 and a negative earning call as having a sum less than 1.5. These thresholds give a roughly equal number of instances over the past 14 years. We took these thresholds and compared returns for different time periods following the Earnings Call. Time periods were subsequent Open-to-Close; subsequent Close-to-Close, subsequent week return, subsequent month return, and subsequent quarter return. Since earnings calls are spaced throughout the year, it is difficult to compound the subsequent returns. Instead, we will be looking at average excess returns for each threshold. The excess return for each security is calculated by subtracting the SPY return of the same time frame from the securities return. Our hypothesis is that the average excess returns for the extremely positive earnings calls will be higher than those for negative earnings calls. We calculated returns of all instances since the end of 2009.

For long-term holdings, the average excess return for high sentiment earnings call companies was strongly positive. On the contrary, negative sentiment earning calls company returns were negative for every time frame. Quarterly returns highlight the importance of a positive earnings call as the average excess return is close to .8% higher than negative. The biggest takeaway from different time periods was the large difference in returns between the next Open-to-Close and the next Close-to-Close, especially those with a high sentiment. Entering on the subsequent close rather than open dropped the excess returns by .8% and made them negative. The next close to close returns were negative regardless of the sentiment threshold. Waiting to enter removed the benefit of positivity from high sentiment. We looked at the returns of these two-time frames with high sentiment over the past 13 years.
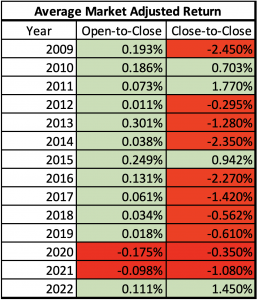
Looking at the past 14-year performance: The Open-to-Close excess returns were positive 12/14 years and Close-to-Close excess returns were positive 4/14 years. The two negative years for the Open-to-Close also came during an abnormal period of the COVID-19 pandemic. Immediate open to close return benefits from the high sentiment far more than the close to close. Therefore, there is a premium on knowing the sentiment of an Earnings Call in real time and entering the next open to maximize short term returns. Instead of manually reading earnings calls to gain insights, traders can use the sentiment summarized by Social Market Analytics to select positions. Waiting to enter on positive earnings calls generally hurts the short-term returns. Social Market Analytics’ scoring on Earning Calls can give traders the advantage of entering the position as quickly as possible for immediate returns, while also providing a holding option for quarterly returns.
If you are interested in learning more about how SMA’s Earnings data can help your trading strategies, please email us at contactus@socialmarketanalytics.com or schedule a demo using this link.
Explore sentiment on earnings calls and all corporate filings on the SMA Unstructured Data Terminal below.
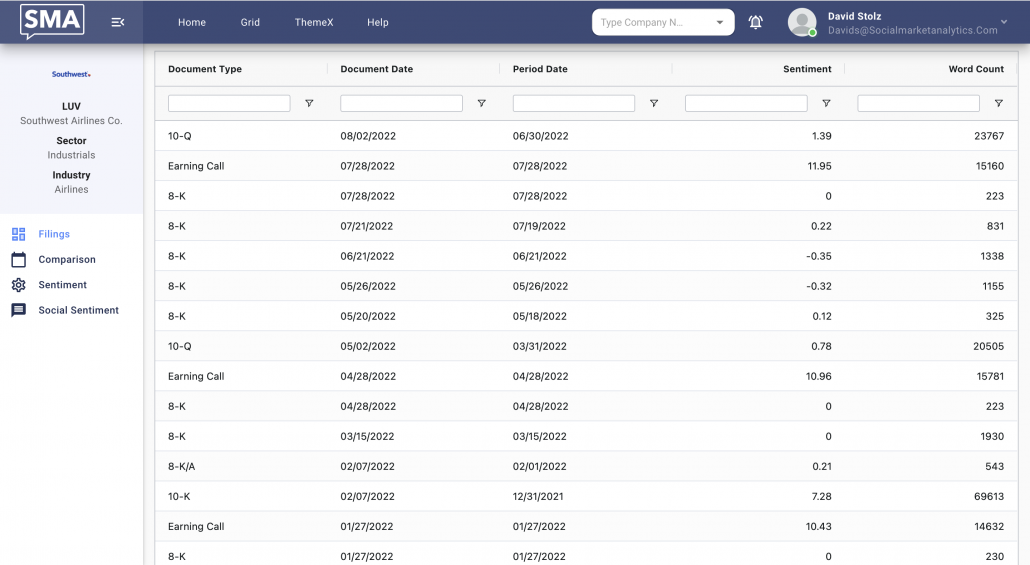
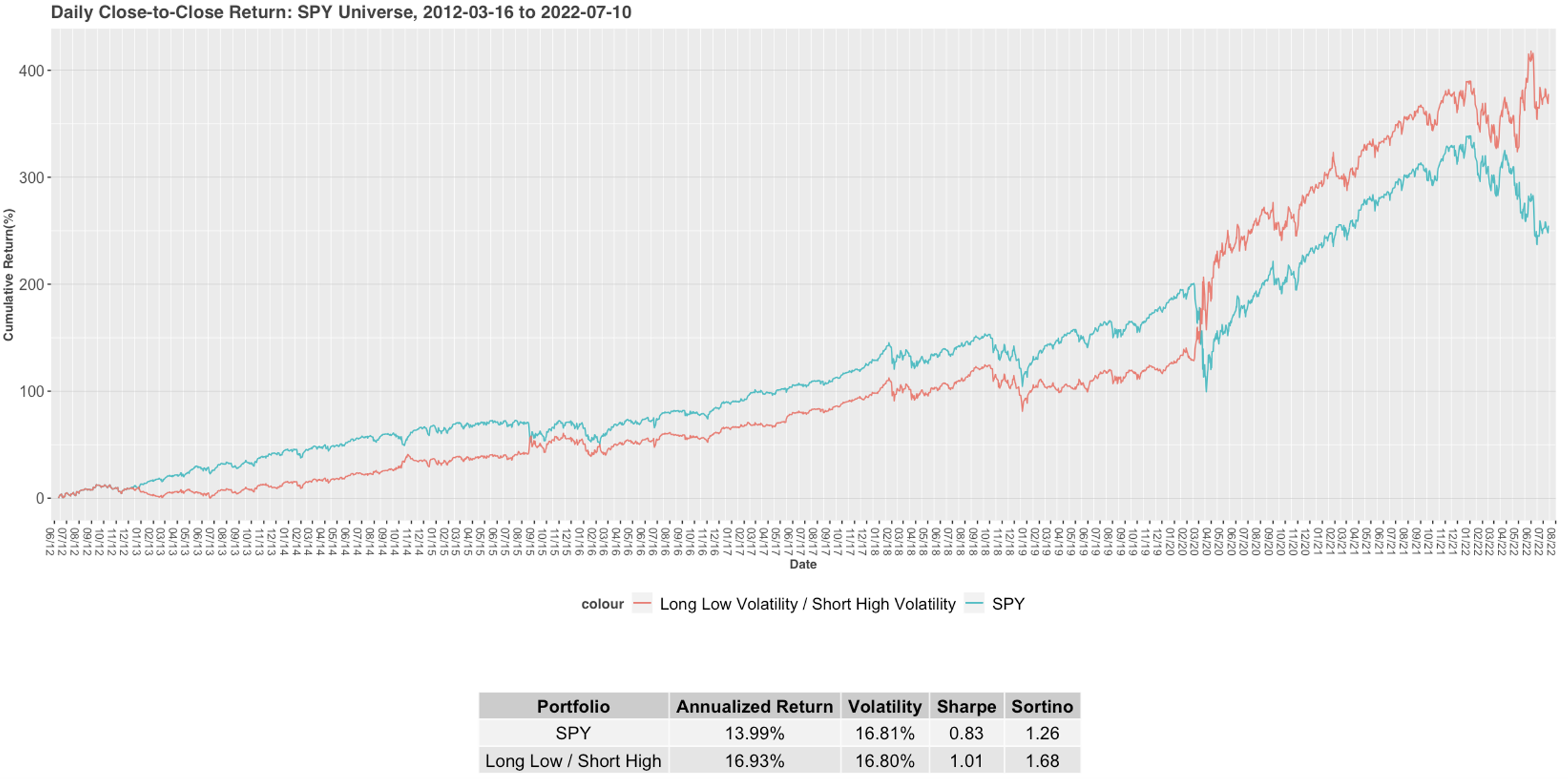
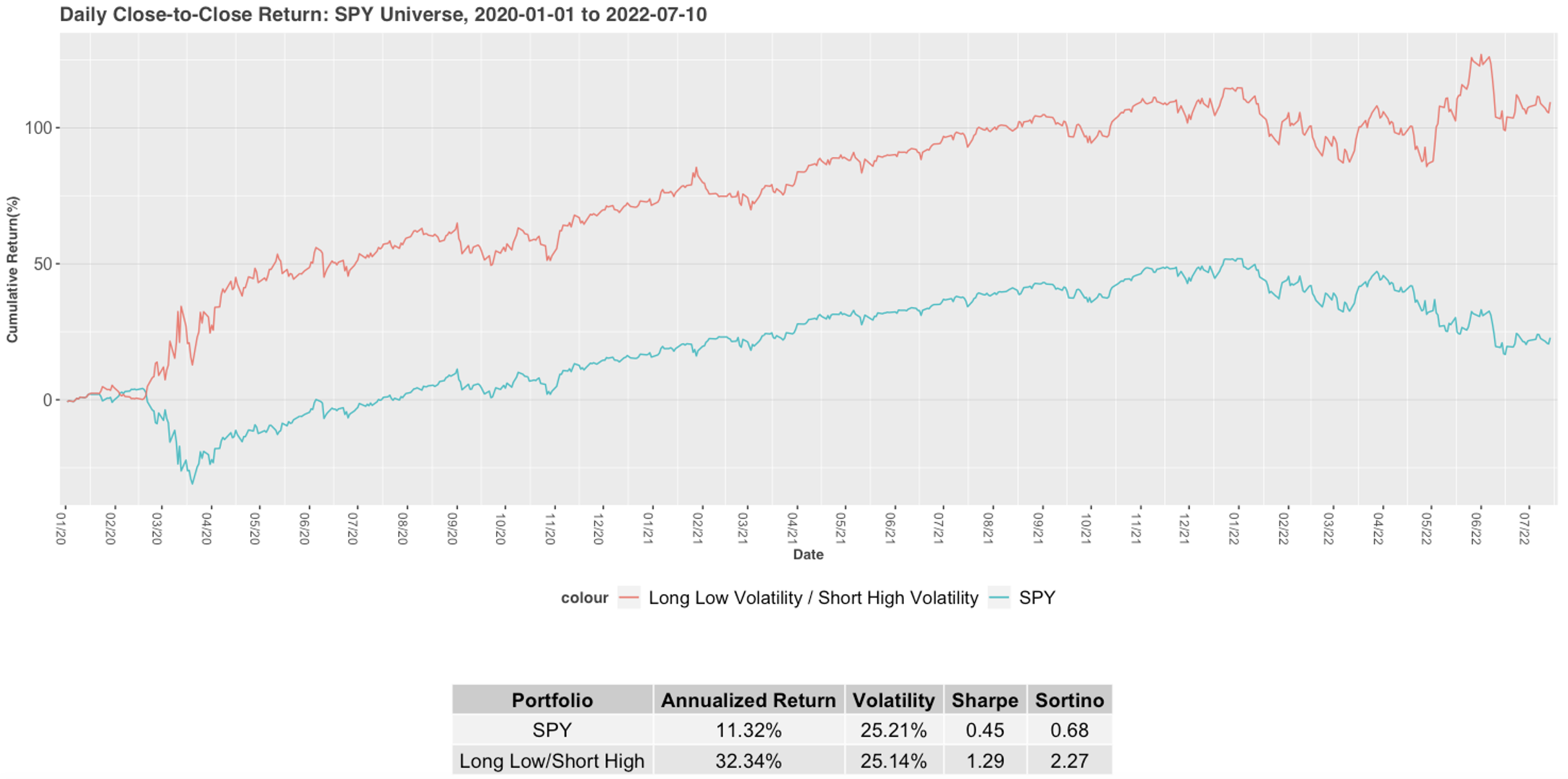
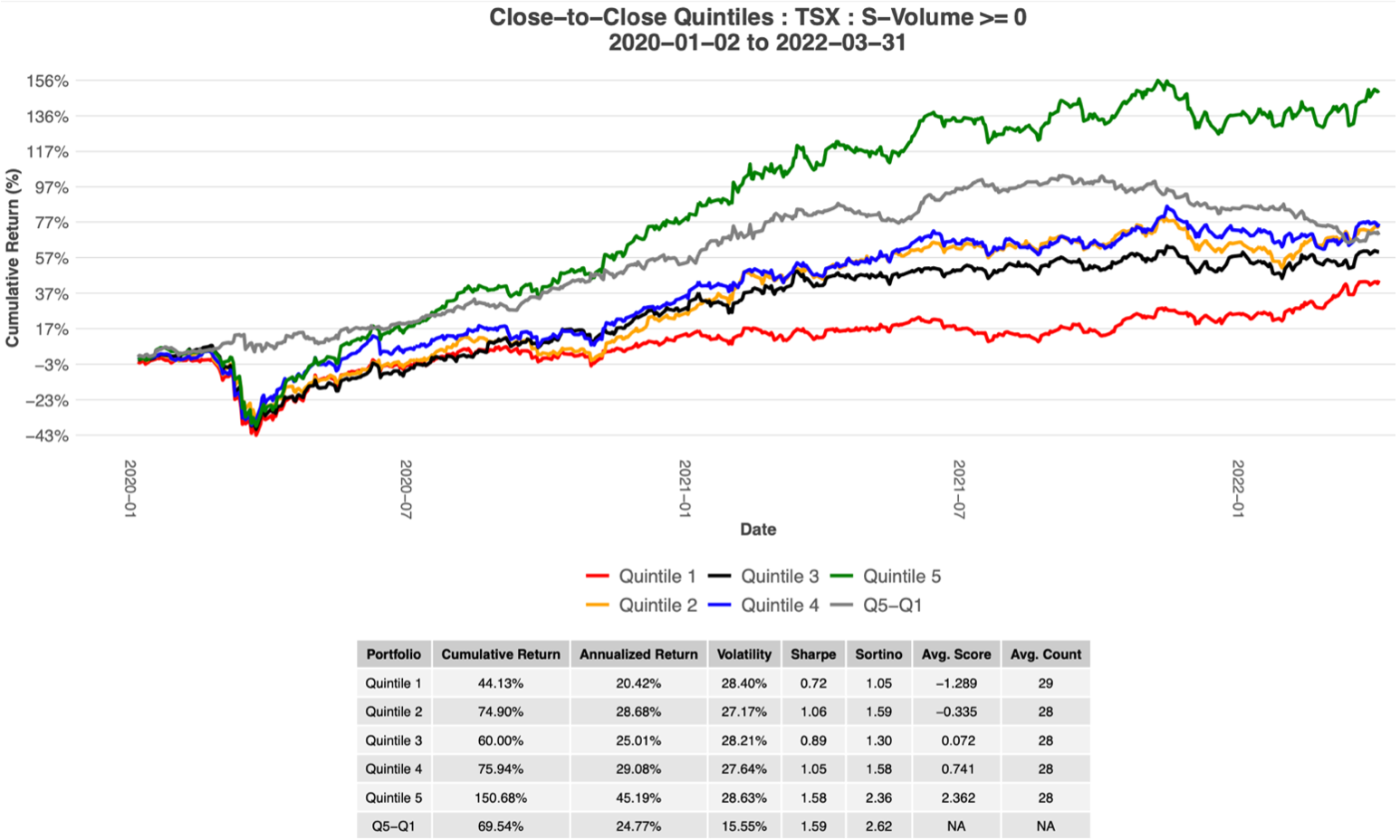
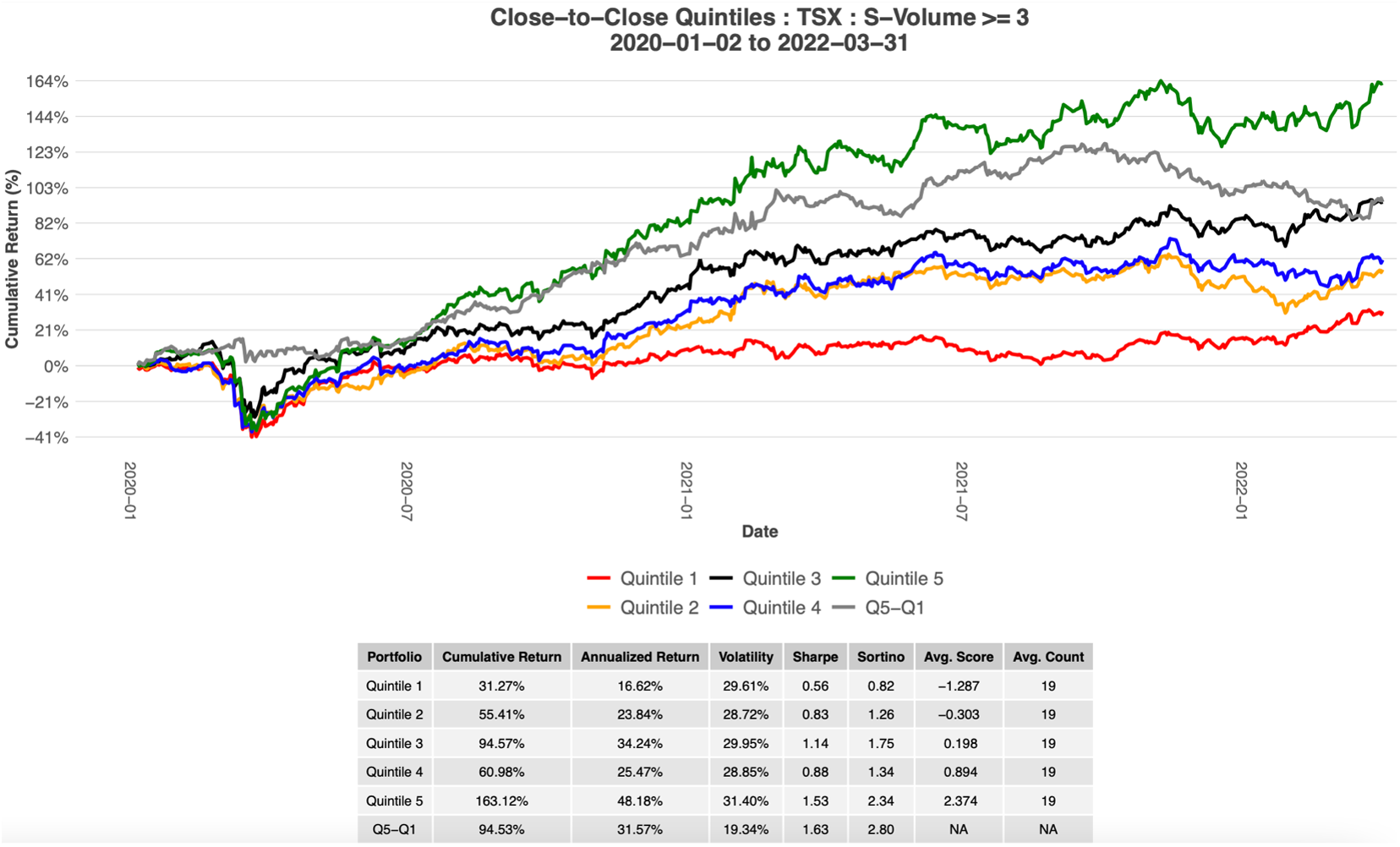
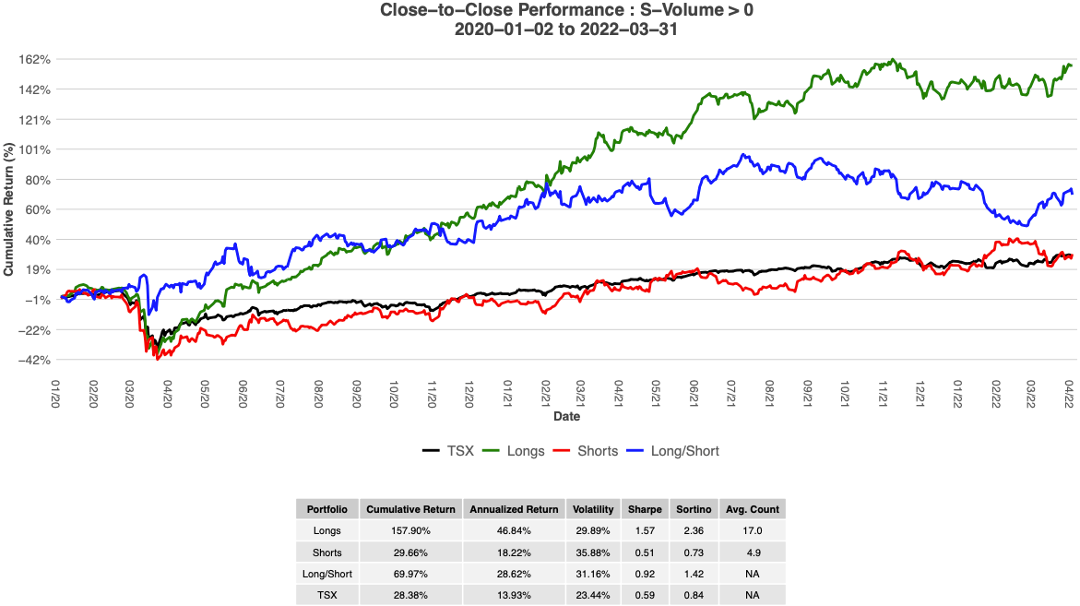

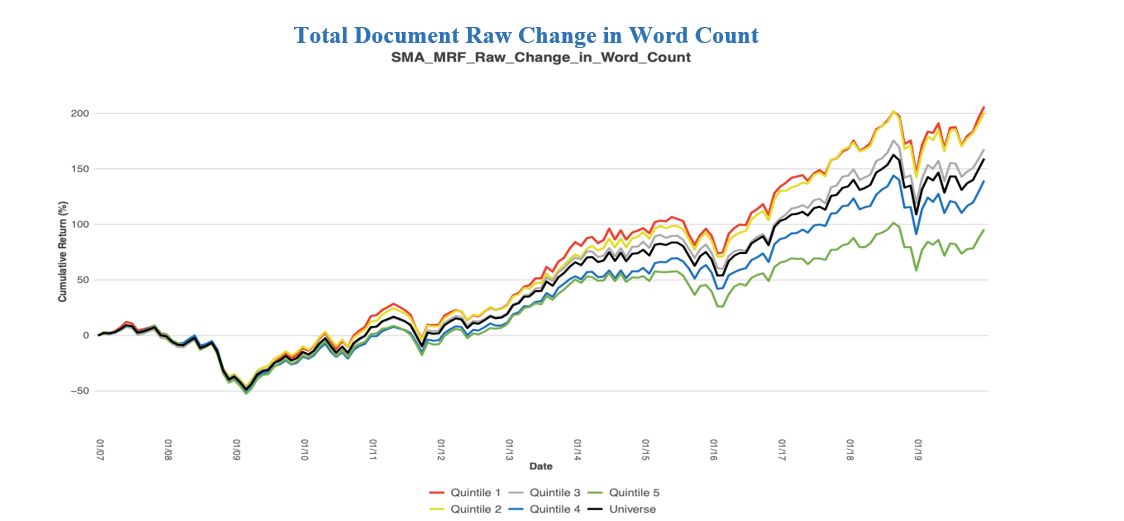
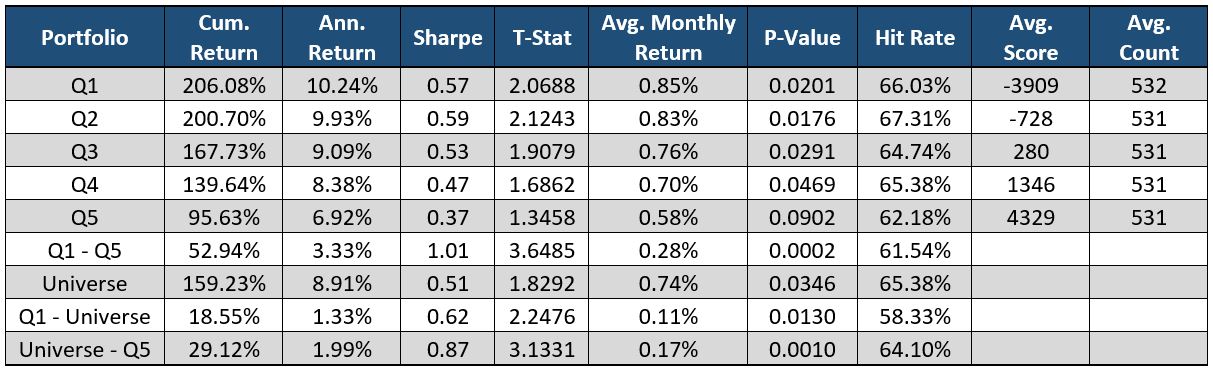
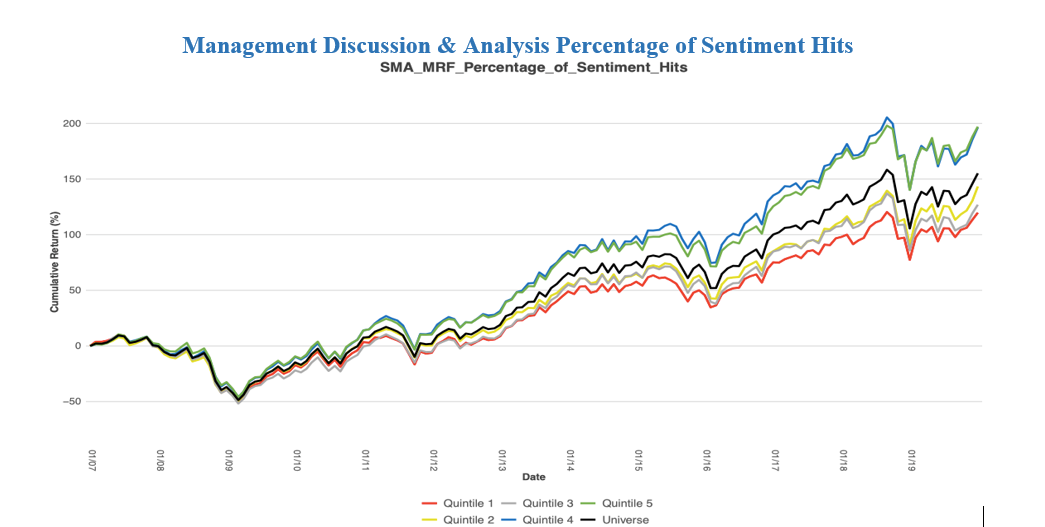
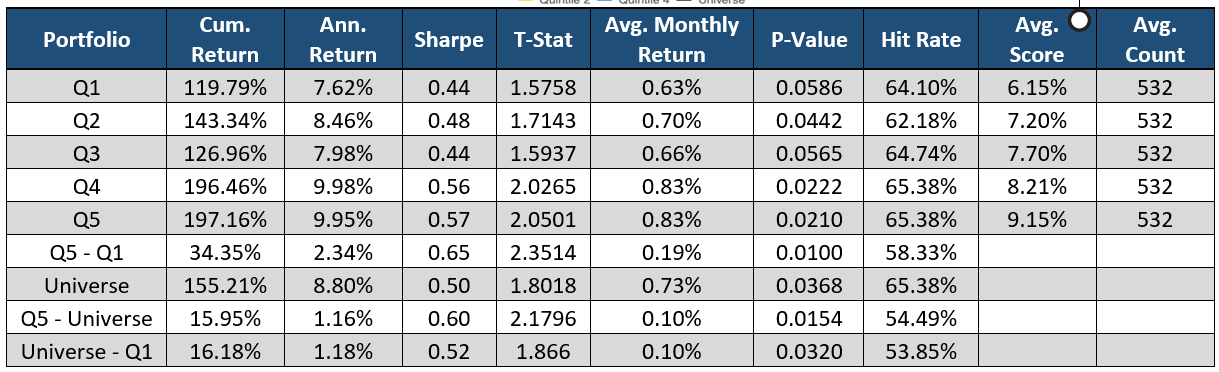
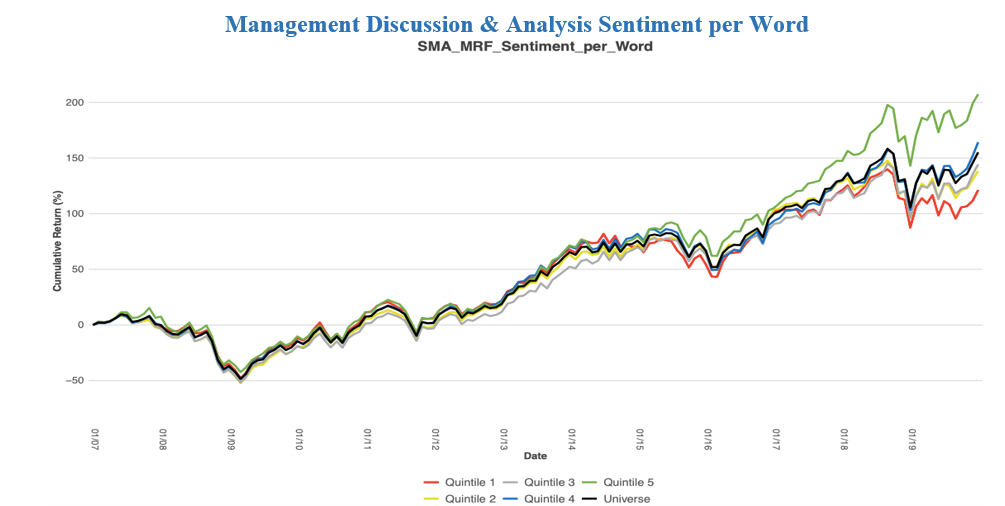
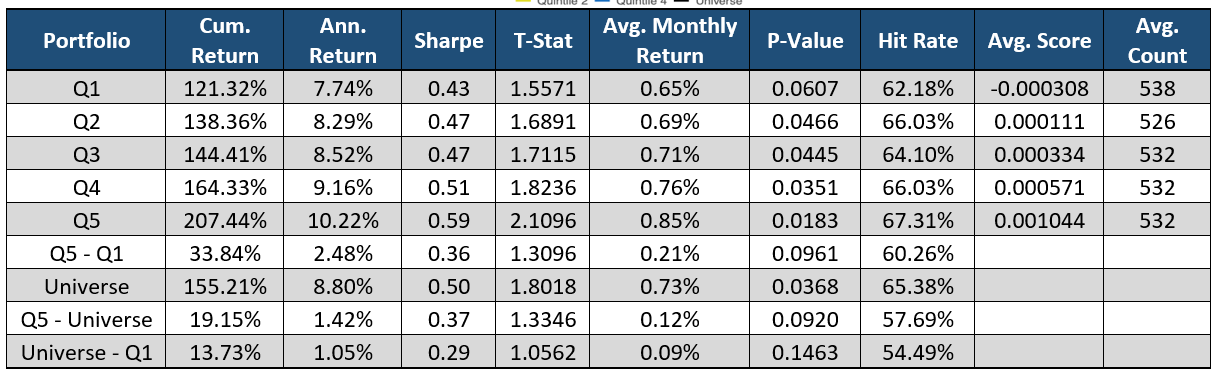
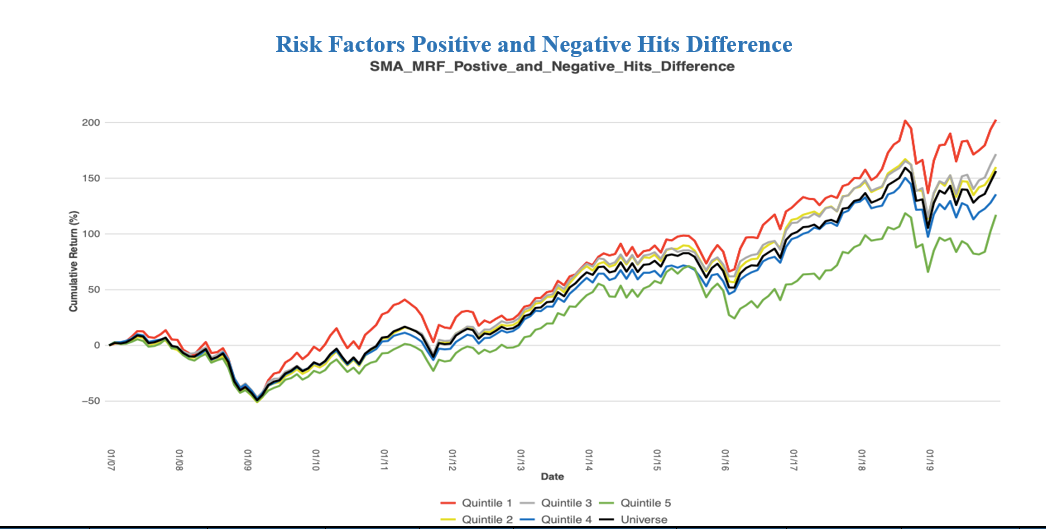
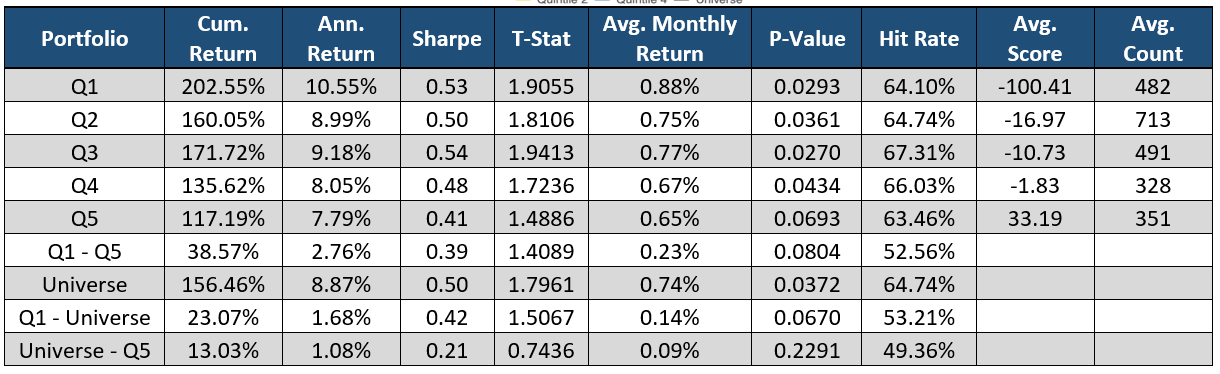
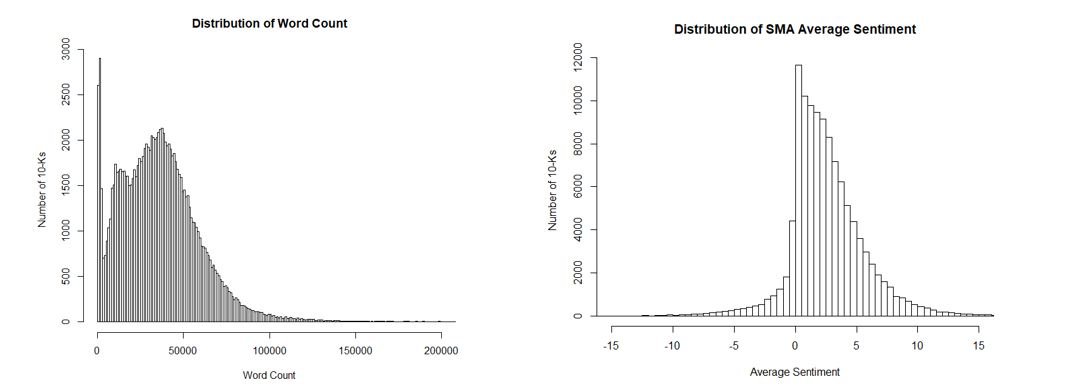
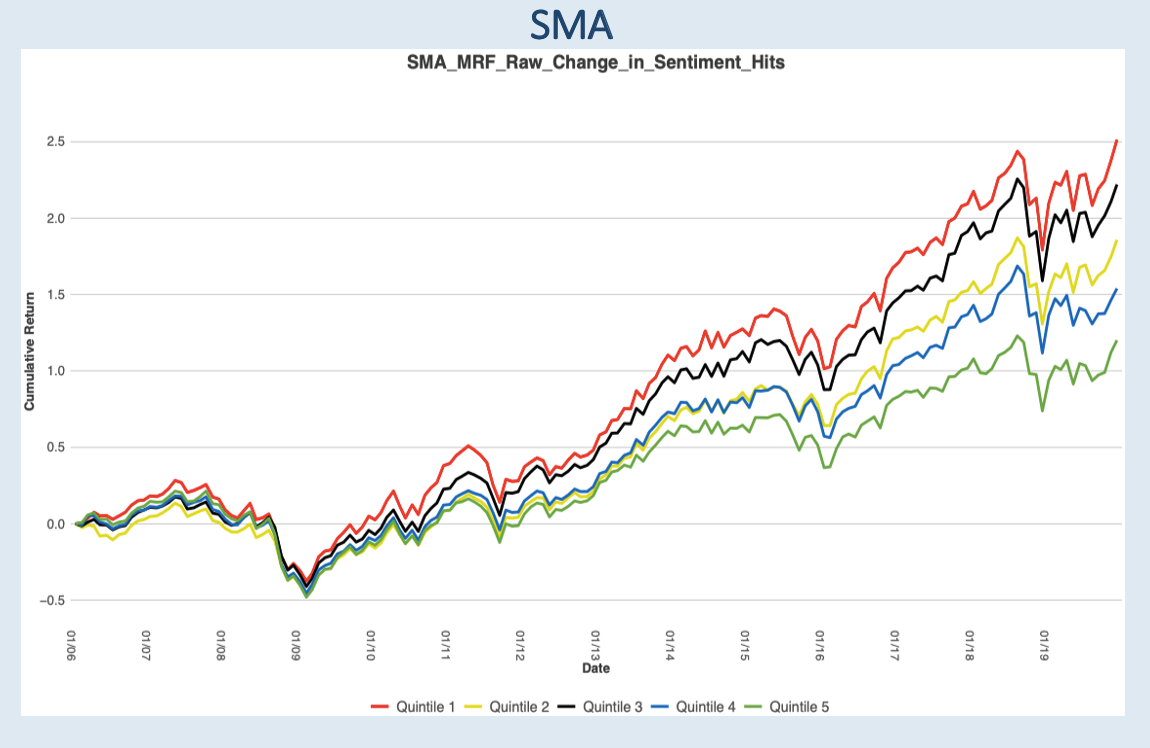
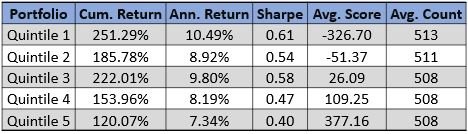
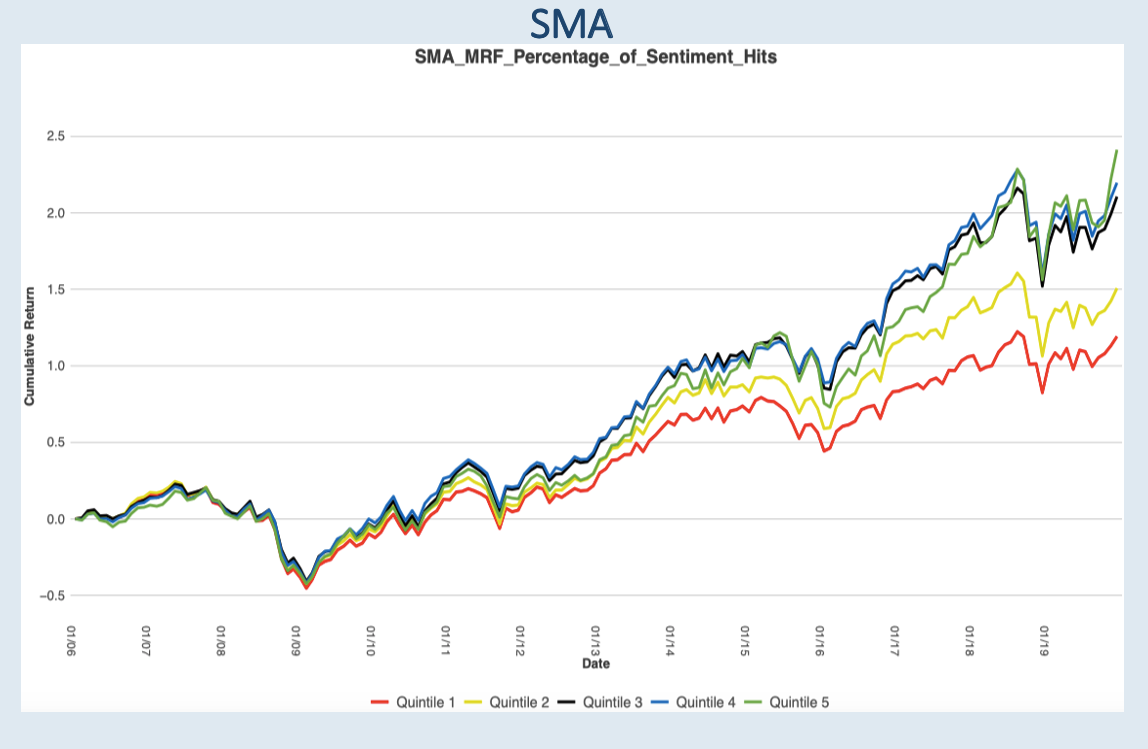
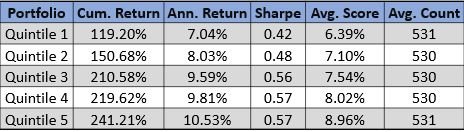
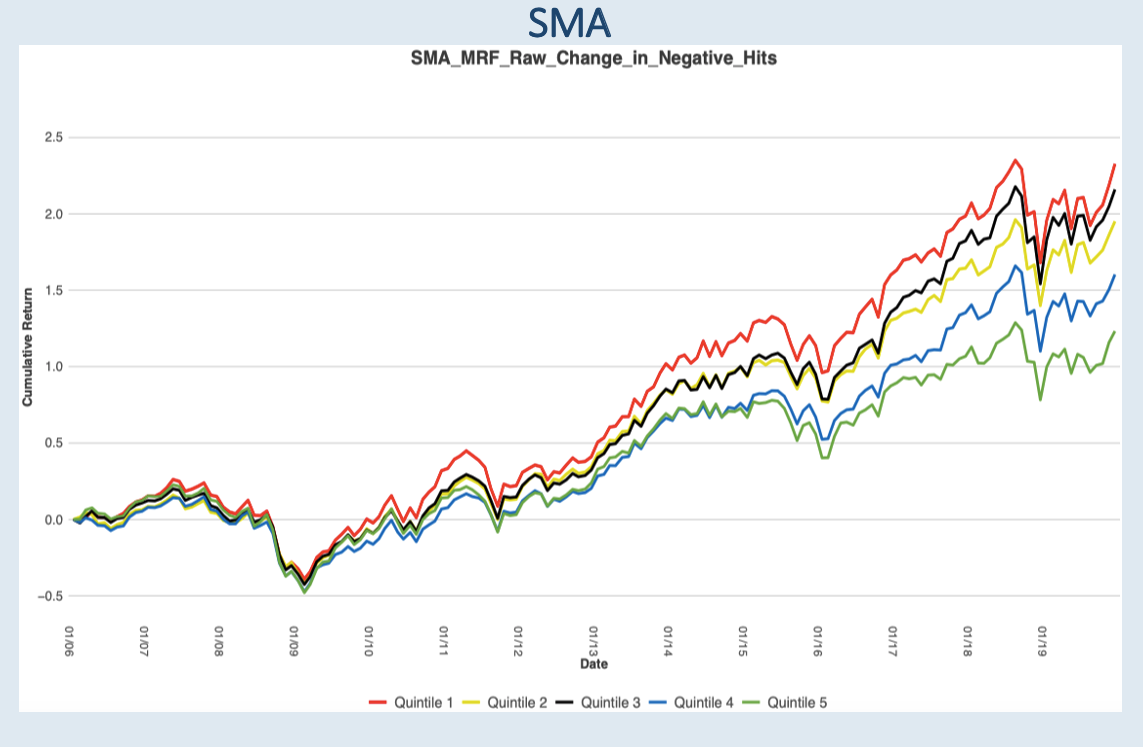
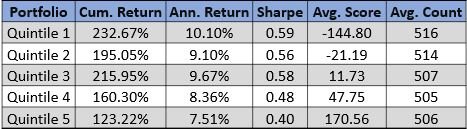
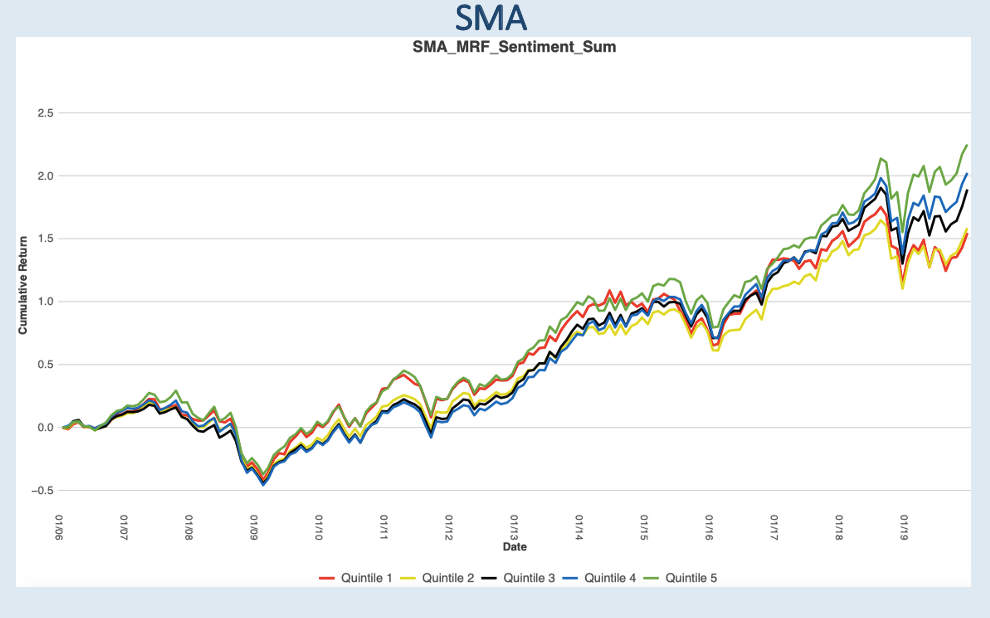
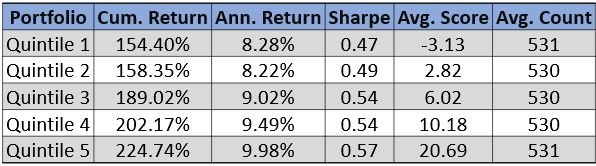
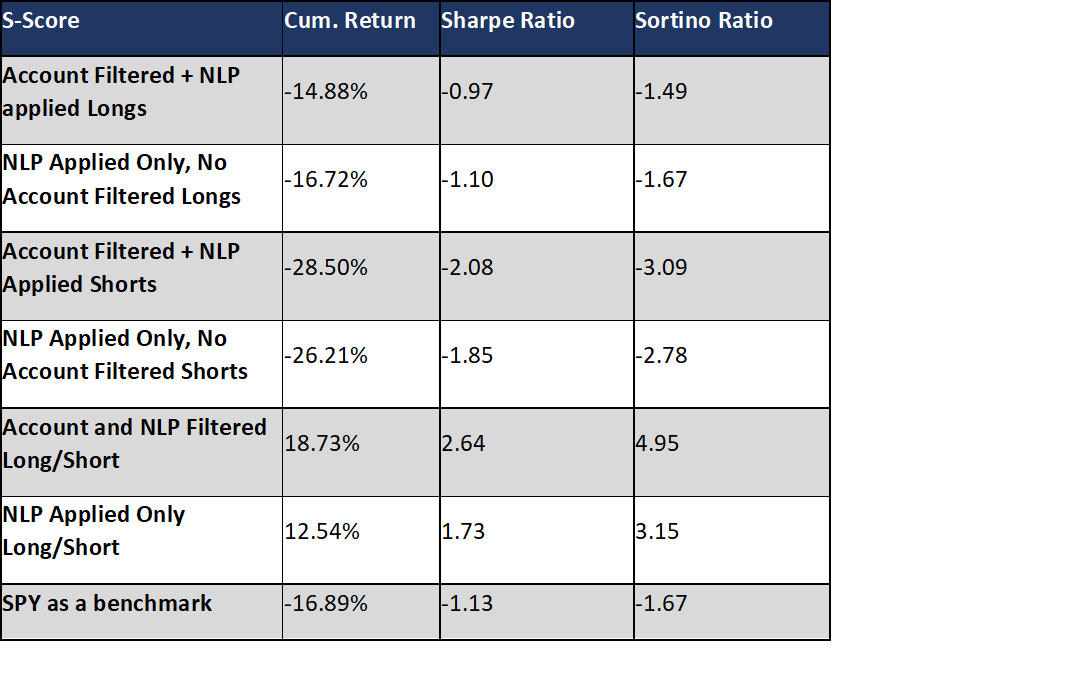 Please contact us with any questions or to see how SMA’s NLP and filtering capabilities can be used in your investment process. ContactUs@SocialMarketAnalytics.com
Please contact us with any questions or to see how SMA’s NLP and filtering capabilities can be used in your investment process. ContactUs@SocialMarketAnalytics.com