A Leader in Unstructured Financial Data
SMA scans data looking for mentions of companies, tickers, names, products… Anything that tells us social media comments are describing a security. We store, filter, and publish metrics on these social media conversations. We filter for the intentions of professional investors; in the end only about 10 percent of the social media conversations make it into our metrics.
When I am discussing social media and finance one question is always asked, “How big is social media and how is it used in Finance?”
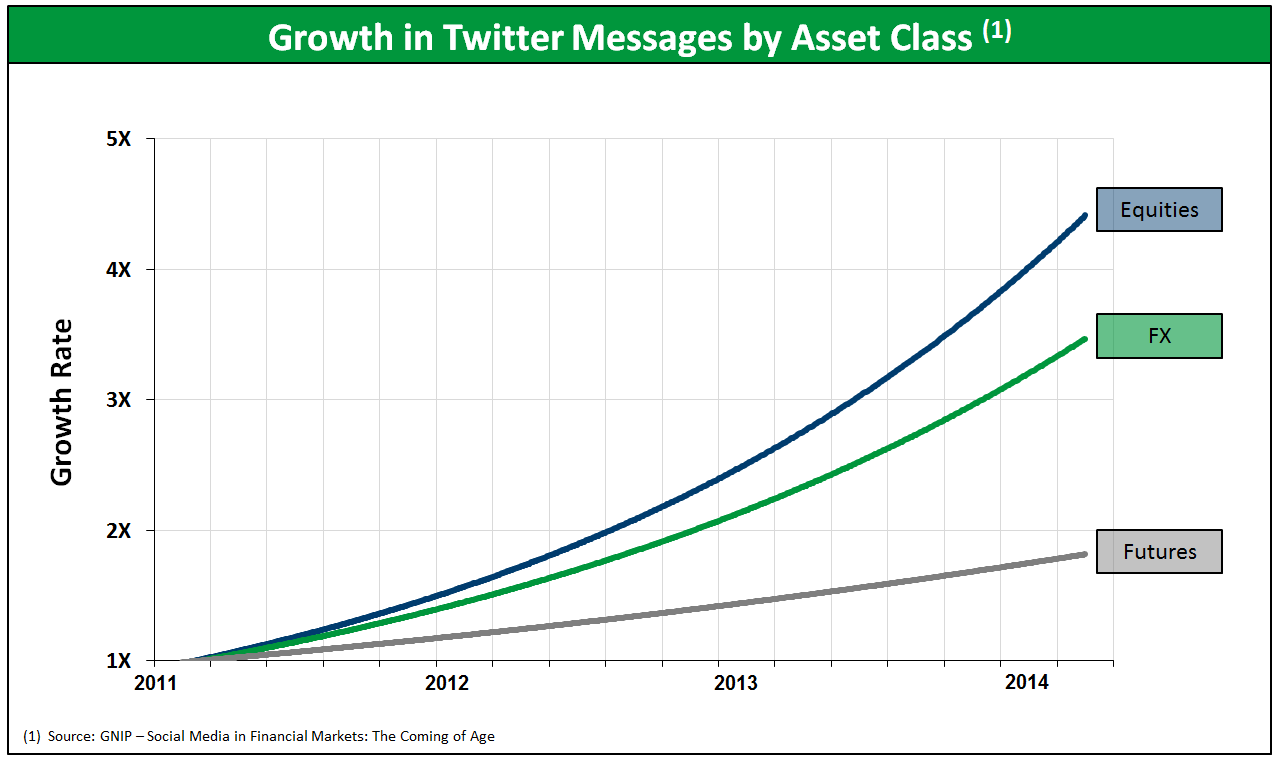
There are over 500 million Tweets per day with over 250 million active Twitter accounts per month. The StockTwits community has over nine million page views per month. As you can see from the chart below the growth in social media discussions spans all asset classes.
The challenge is to filter the noise and return a clean statistically significant signal representing the intentions of professional investors. To meet this objective you need to: Identify the Tweet is about a security, eliminate people trying to manipulate sentiment, identify professional investors, and calculate the sentiment correctly.
Identifying commodities and currencies is especially challenging: “This is gold” or “This is oil” mentions gold and oil respectively but they certainly aren’t taking about Gold Bullion or Crude Oil. The Cashtag has helped in identifying the Tweet is about a security. Typically professional investors will identify a security with “$”. $AAPL tells the Twitter community this Tweet is about the security Apple, $NG_F is referencing Natural Gas. It is important that the security model identifies different identifiers for the same security. This is common in the currency market where currencies are frequently identified with slang. When calculating sentiment on commodities it is important to identify that a specific contract, the front month, and cash may all be referenced by the same identifier. An expansive topic model is usually applied to this challenge.
Social media is like every means of communication, there are spammers, scammers and con-artist. Our definition of professional investor does not mean strictly analyst at major firms, identifying all active traders is important. SMA uses advanced algorithms to qualify professional investors. How long the account has been active, how often they Tweet about securities and how often their Tweets are retweeted are just some of the metrics used by our algorithms to identify influential professional investors and eliminate scammers. As an example, people who Tweet sporadically and then send many Tweets in succession are more likely to be attempting manipulation.
Once professional investors are identified the key is to score and aggregate their forward-looking Tweets. A tweet saying they bought CL_F two days ago doesn’t help predict CL_F today. Using a natural language processor you can identify the Tweets that are forward-looking: “going long”, “buying puts”, “selling puts”, “raising price target”, “raising rating”, “hitting support”, “broke through resistance” are all representations of trader expectations of price movements. We have found that after filtering you should end up with about 10% of the original data.
Sentiment calculation itself has evolved significantly in recent years. The most common processes involve using a Natural language Processor (NLP) to break the text into components (Tokenization). Then use a dictionary to assign scores to words and phrases (bi-grams & tri-grams). The scores are aggregated per Tweet and across a period of time. There are three types of scoring. Two Bucket Rough Grain Scoring classifies tweets as positive or negative. This scoring method over weights neutral Tweets and under weights extreme Tweets. Three Bucket Rough Grain scoring adds a bucket for neutral Tweets but still suffers from under weighting extreme positive or negative Tweets. The most accurate method is Fine Grain Scoring that assigns a score to each tweet and does not have the over or under weighting problem. These three methodologies can generate very different aggregate sentiment values.
Thanks,
Joe Gits
Leave a Reply
Want to join the discussion?Feel free to contribute!