Social Market Analytics, Inc. (SMA) has partnered with S&P Global Market Intelligence to create Machine Readable Filings (MRF), which provides textual data of U.S. Securities and Exchange Commission (SEC) EDGAR filings broken down to sub-levels with text underneath. Textual data is parsed to create historical baselines for 10-Ks, 10-Qs, 8-Ks, 20-Fs and other filings. This blog demonstrates the advantages of using the MRF parsed filings versus the filings on SEC Edgar. This deck uses the Snowflake view of MRF, however, MRF is also available on Xpressfeed.
The following examples are a comparison of the most recent Nike, Inc. 10-K filing published on July 24, 2020 from the SEC Edgar filing on the left and the Snowflake view of MRF on the right. The first thing to point out is how to read the MRF Snowflake file. The first four columns: COMPANYID (Unique company identifier), COMPANYNAME, FILINGDATE (date the filing is published) and PERIODDATE (last date of the reporting period) will have the same values in every row since we are analyzing one document for one company. Each level of the document - the document, the parts, the items, and the subsections - gets a HEADINGID. The hierarchy of the document shown in the original document on EDGAR is represented tabularly with the PARENTHEADINGID. Each row in the document contains a PARENTHEADINGID which represents the HEADINGID of the next level up in the hierarchy. The STANDARDIZEDHEADING is used for common headings across all of the same document types. SECTIONTEXT is the text within the subsection.
The first picture is an example of the document broken down to the item level. All of the HEADINGIDs will be at the item level or higher for the MRF Snowflake image. The image from SEC Edgar is the table of contents from the document. Shown below are examples of the STANDARDIZEDHEADING and HEADINGID to PARENTHEADINGID relationship. The advantage of the standardized heading is the ability to compare across multiple companies. Some companies will have Item 1 listed as “Item 1: Business”, others will have “I1 Business” or just “Item 1”. When comparing sentiment or word counts within the items, the standardized heading is necessary to always be comparing the same thing. The advantage of the HEADINGID and PARENTHEADINGID will be discussed later in the blog.

The next image compares the beginning of Item 1 of the respective versions of the Nike 10-K. Again, Part 1 and Item 1 are standardized in the MRF version. Each heading is also grabbed and corresponds to the correct text. Paragraph breaks in the SECTIONTEXT are indicated by the “\n”. The PARENTHEADINGID and HEADINGID relationship is also shown. This time each section header refers to the item in which it belongs. Parsing down to the section header level allows for more in-depth analysis. For example, if there is a large word count change or a key word in “Products” that means there is likely a change in the products Nike is offering or the key word is incorporated into their products. If the lowest level of parsing was the item level, then a large word count change in one section might not even be detected if other sections increase in length.
The same detailed parsing is also applied to the notes and exhibits, allowing for the same fine grain analysis. Companies often hide key information within the notes and can indicate early signs of potential problems for a company.

When parsing the exhibits, MRF is able to extract the exhibits and roll them up with the actual filing into one JSON or Snowflake file, whereas in Edgar, the exhibits are in a separate html file. The exhibits are also standardized because companies write exhibits in different formats.

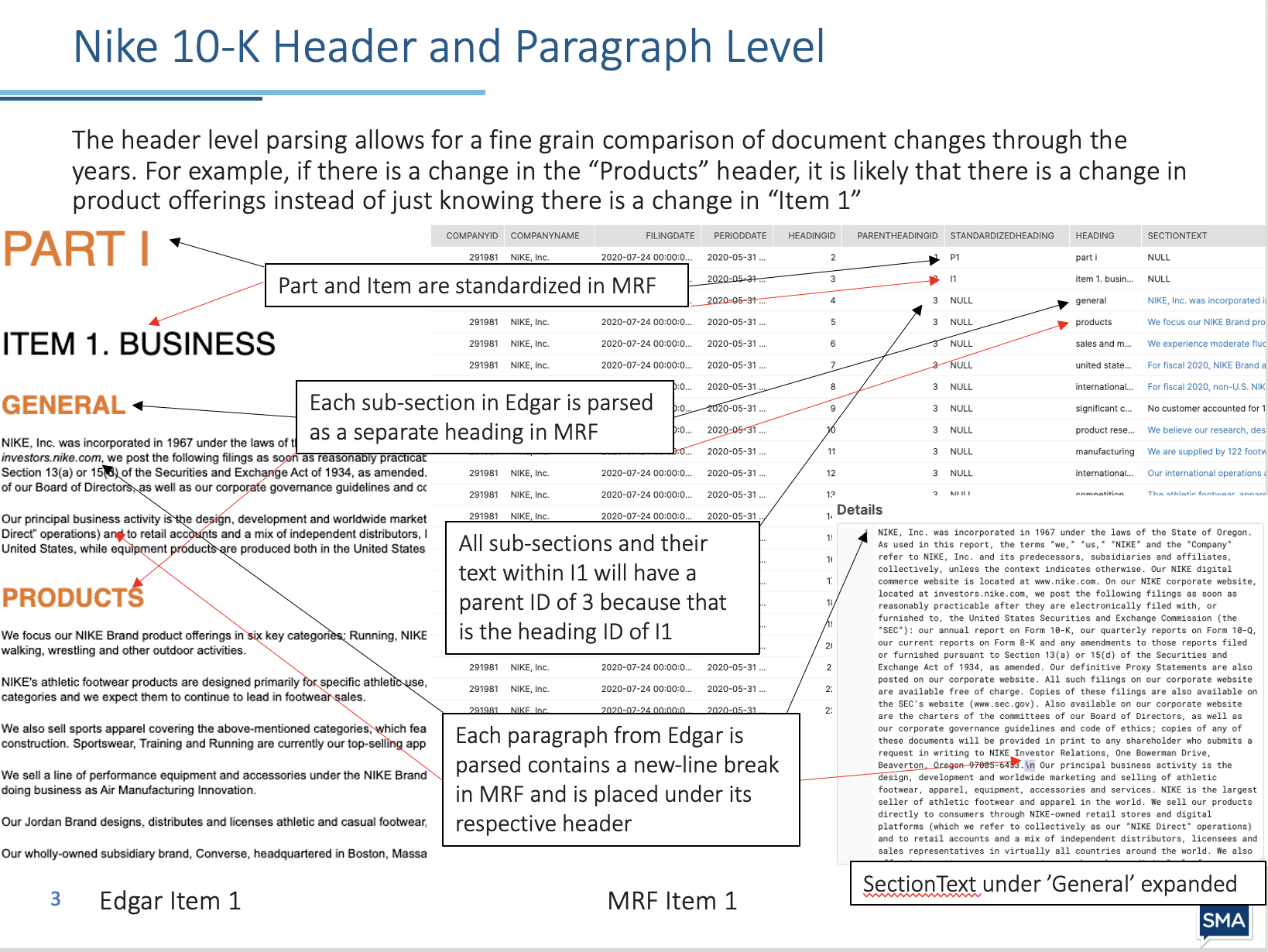
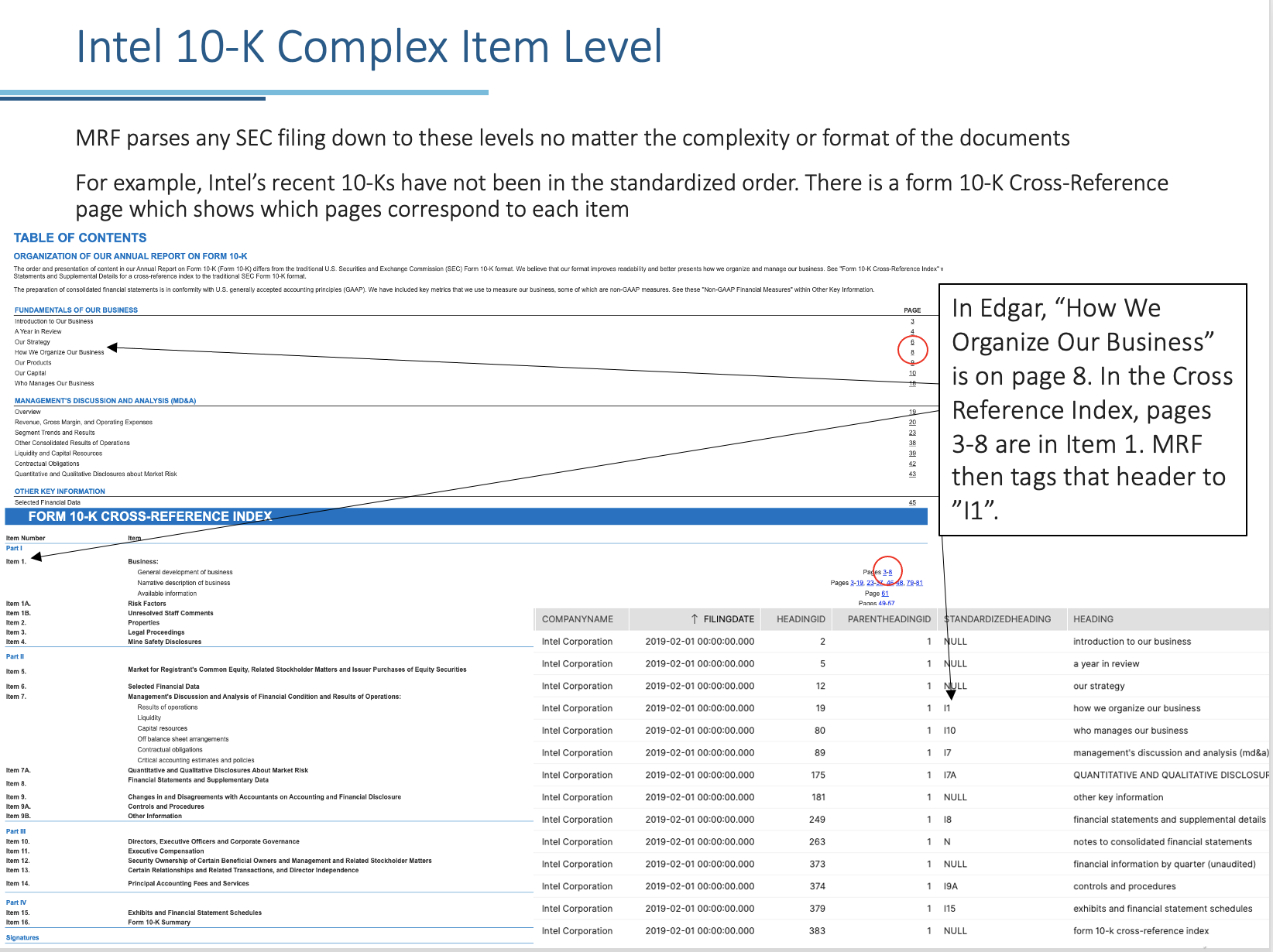
All the examples above are from a fairly regular formatted 10-K. Some companies, such as Intel, will publish their filings not in the standard order and have a cross-reference index at the end to correspond to the correct items. For these filings, MRF creates a template that will automatically parse future filings from that company into the correct format.
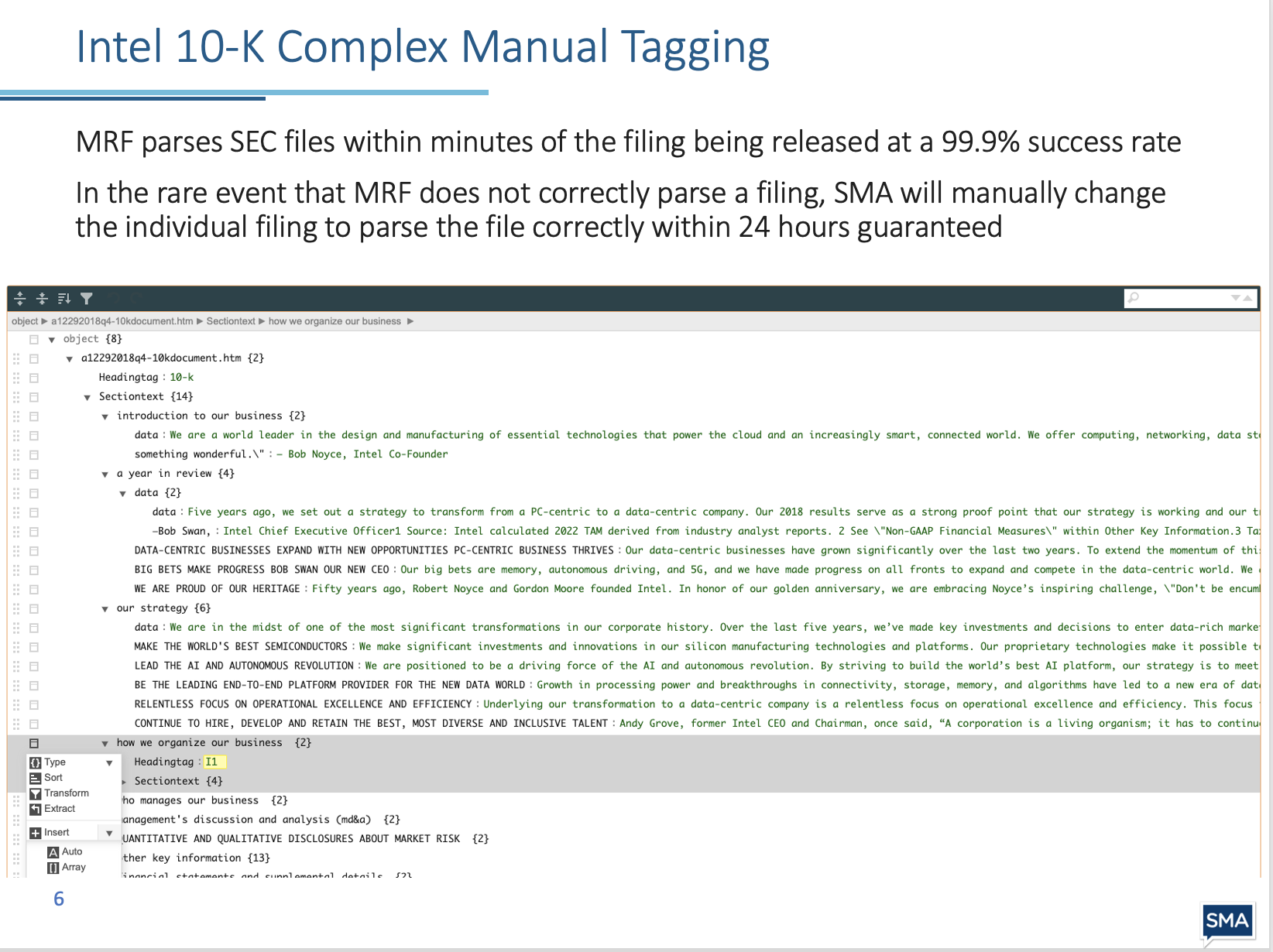
MRF parses SEC files within minutes of the filing being released at a 99.9% success rate. In the rare event that MRF does not parse a filing correctly, SMA will manually change the individual filing to get the correct parsing within 24 hours guaranteed, using the manual parser shown below.
Until now there has been no real way to analyze text in corporate filings. SMA’s Machine Readable Filings product allows for the most concise way to view these filings. For more information or to start a trial ContactUs@SocialMarketAnalytics.com.